BPF简介【第一章】
BPF最初作为一种网络数据包过滤器而诞生,但在Linux内核的不断发展中,演变为一种通用的内核执行引擎,具备安全、可编程、性能开销低等优势。现代BPF(常称为eBPF)已广泛应用于以下场景:
- 系统性能分析与故障排查(如
bpftrace, perf, BCC工具)。 - 网络监控与安全(如
Cilium, XDP)。 - 内核行为观测与动态扩展(如
tracepoints, kprobes, uprobes等)。
🌲 什么是Tracing(追踪)、Snooping(监听)、Sampling(采样)、Profiling(性能分析)与 Observability(可观测性)?
这些术语都用于对分析技术与工具进行分类。
Tracing是一种基于事件的记录方式——这也是BPF工具所采用的插桩类型。你可能已经使用过一些专用的追踪工具。比如 Linux的strace(1),它可以记录并打印系统调用事件。还有许多工具并不追踪事件,而是通过固定的统计计数器来测量事件并打印汇总信息,例如Linux的top(1)就是一个例子。
也就是说,
top并不像strace、perf、或BPF工具那样注册钩子来监听特定事件的发生,而是周期性地读取/proc文件系统中的信息,比如:
/proc/stat/proc/[pid]/stat/proc/meminfo/proc/loadavg通过比较当前轮询与上一次轮询之间的数值变化,
top计算出CPU占用率、内存使用、进程状态等。
追踪器的一大特点是能够记录原始事件及其元数据。这类数据通常非常庞大,因此可能需要进行后期处理以生成汇总信息。借助BPF所实现的可编程追踪器,可以在事件发生时运行小型程序,动态生成自定义的统计汇总或执行其他操作,从而避免昂贵的后期处理开销。
虽然strace(1)名字中有trace字样,但并非所有追踪器的名字都如此。比如tcpdump(8)就是一个专用于网络数据包的追踪工具。(也许它本该叫做tcptrace?)Solaris操作系统中有个类似于tcpdump的工具,名为snoop(1M),之所以叫 snoop,是因为它用于监听网络数据包。我曾在Solaris上开发并发布了许多追踪工具,当时(也许是个错误)采用了 snooping这一术语,用来命名早期工具。这就是为什么现在有execsnoop(8)、opensnoop(8)、biosnoop(8)等等。Snooping、事件转储(event dumping)与tracing通常是指同一种操作。后续章节会详细介绍这些工具。
除了工具名称以外,tracing这个术语在内核开发者中也被广泛使用,尤其是当谈论使用BPF进行可观测性分析时。
Sampling工具则是从大量测量数据中提取部分样本,以便粗略勾勒出目标系统的状况;这类方法也称为创建profile(性能画像)或profiling(性能分析)。BPF工具中有一个名为profile(8)的工具,它通过定时器对运行中的代码进行采样。例如,它可以每10毫秒采样一次,换句话说,就是每秒(在每个CPU上)采集100个样本。采样器的一个优点是性能开销可能低于追踪器,因为它们只测量所有事件中的一小部分。但缺点是采样只能提供粗略的系统视图,并可能漏掉某些事件。
Observability指的是通过观察来理解系统行为,它也用来统称那些实现这一目的的工具。这些工具包括追踪工具、采样工具以及基于固定计数器的工具。但不包括基准测试工具(benchmark tools),因为后者通过执行工作负载实验来改变系统状态。
🌲 什么是BCC、bpftrace和IO Visor?
直接编写BPF指令极其繁琐,因此出现了一些前端工具,提供更高级的语言接口来简化开发。用于追踪任务的主要前端BCC和bpftrace。
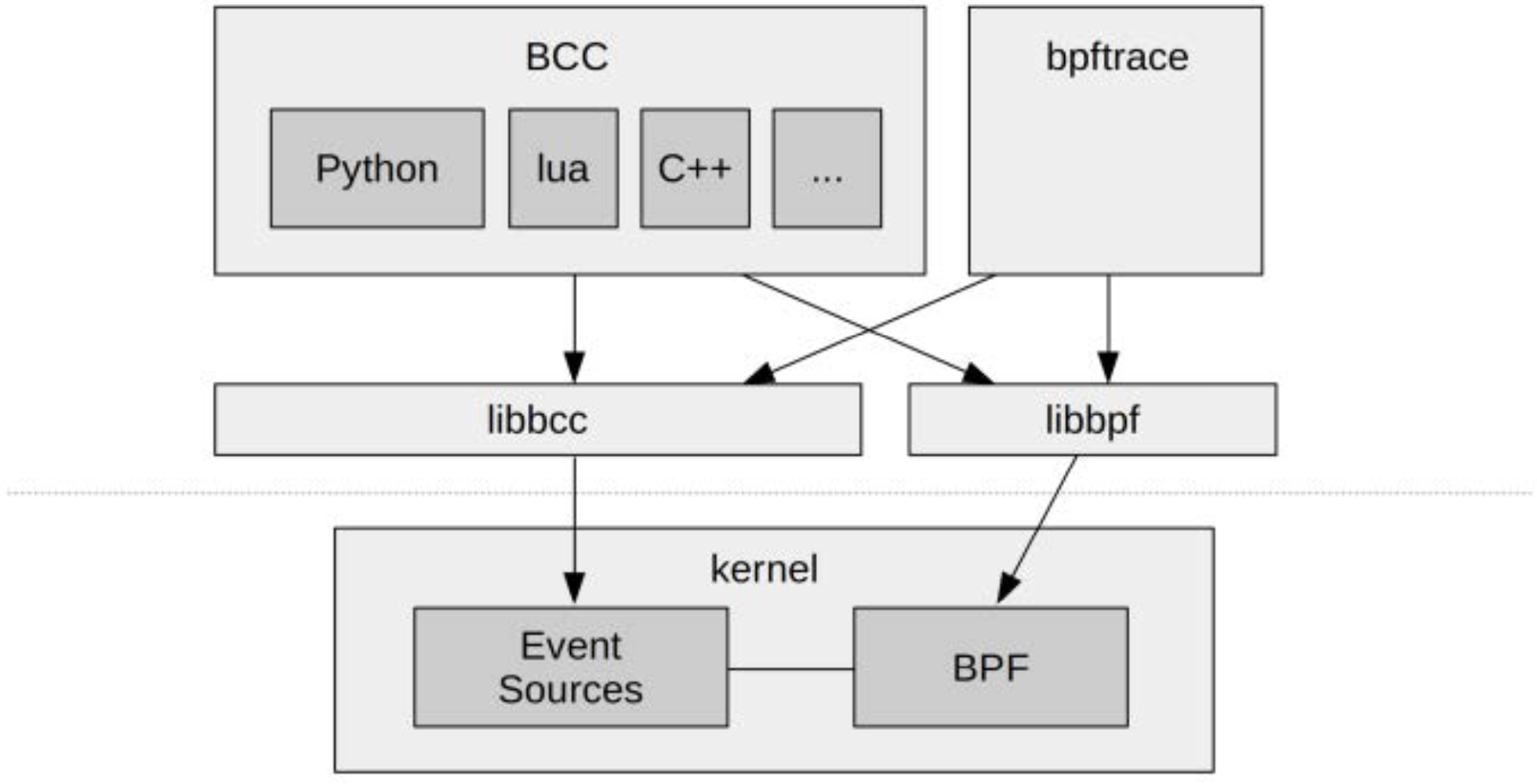
BCC(BPF Compiler Collection)是第一个为BPF开发的高级追踪框架。它提供一个用于编写内核BPF程序的C语言环境,以及用于用户态交互的多种语言接口,如Python、Lua和C++。BCC也是libbcc和现今广泛使用的libbpf库的起点,这些库提供了在内核事件上插桩(instrumentation)并加载BPF程序的功能。BCC仓库中还包含70多个现成的BPF工具,用于性能分析与故障排查。你可以直接安装BCC并运行这些工具,而无需自己编写任何BCC代码。本书将带你逐步了解其中的多个工具。
bpftrace是一个较新的前端,提供了专门为BPF设计的高级领域特定语言(DSL)。bpftrace的代码非常简洁,因此本书通常会直接展示工具的源码,以便说明它们是如何插桩并处理事件的。bpftrace构建于libbcc与libbpf之上。
如图1-1所示,BCC与bpftrace是互补的:
bpftrace适用于强大的“一行命令”和小脚本的快速开发;BCC更适合构建复杂的脚本或常驻后台的服务程序,并且可以集成其他语言库。例如,许多Python编写的BCC工具使用了Python的argparse库,以实现对命令行参数的复杂控制。
另一个BPF前端工具ply也正在开发中,它的设计目标是轻量、依赖最少,非常适合嵌入式Linux环境。如果ply更适合你的使用场景,本书依然具有指导价值——书中展示的bpftrace工具大多数都可以在转换为ply语法后运行。(未来的ply版本可能直接支持bpftrace语法。) 本书聚焦于bpftrace,是因为其发展更为成熟,并具备全面的功能,能够胜任所有的BPF分析任务。
需要注意的是,BCC与bpftrace并不属于Linux内核源码的一部分,而是由Linux基金会旗下的一个GitHub项目——IO Visor所维护。项目地址如下:
- https://github.com/iovisor/bcc
- https://github.com/iovisor/bpftrace
在本书中,BPF tracing一词通常泛指使用BCC或bpftrace工具进行的追踪分析。
🌲 初识BCC:快速上手
让我们直接进入正题,通过一些工具输出快速感受BCC的威力。下面这个工具用于追踪新进程的启动,并在每个进程启动时打印一行简要信息。
这个工具名为execsnoop(8),来BCC工具集。它的工作原理是追踪execve(2)系统调用,而这个系统调用正是exec(2)系列的一种变体(工具名中的exec即由此而来)。
如何安装BCC工具将在第4章中介绍,后续章节也会逐步讲解这些工具的原理与用法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
$ sudo apt install bpfcc-tools linux-headers-$(uname -r)
$ sudo execsnoop-bpfcc
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:45:9: warning: '__HAVE_BUILTIN_BSWAP32__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP32__
^
<command line>:4:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP32__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:46:9: warning: '__HAVE_BUILTIN_BSWAP64__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP64__
^
<command line>:5:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP64__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:47:9: warning: '__HAVE_BUILTIN_BSWAP16__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP16__
^
<command line>:3:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP16__ 1
^
3 warnings generated.
PCOMM PID PPID RET ARGS
输出结果展示在追踪期间哪些进程被执行了——其中有些进程可能非常短暂,以至于在其他工具中根本看不到。你会看到大量输出行,显示的是一些标准的Unix工具,如ps(1)、grep(1)、sed(1)、cut(1)等。
可以使用execsnoop(8)的-t选项来为输出添加一个时间戳列,从而更清楚地看到事件发生的时间顺序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
$ sudo biolatency-bpfcc -m
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:45:9: warning: '__HAVE_BUILTIN_BSWAP32__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP32__
^
<command line>:4:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP32__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:46:9: warning: '__HAVE_BUILTIN_BSWAP64__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP64__
^
<command line>:5:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP64__ 1
^
In file included from <built-in>:2:
In file included from /virtual/include/bcc/bpf.h:12:
In file included from include/linux/types.h:6:
In file included from include/uapi/linux/types.h:14:
In file included from include/uapi/linux/posix_types.h:5:
In file included from include/linux/stddef.h:5:
In file included from include/uapi/linux/stddef.h:5:
In file included from include/linux/compiler_types.h:148:
include/linux/compiler-clang.h:47:9: warning: '__HAVE_BUILTIN_BSWAP16__' macro redefined [-Wmacro-redefined]
#define __HAVE_BUILTIN_BSWAP16__
^
<command line>:3:9: note: previous definition is here
#define __HAVE_BUILTIN_BSWAP16__ 1
^
3 warnings generated.
cannot attach kprobe, Invalid argument
Traceback (most recent call last):
File "/usr/sbin/biolatency-bpfcc", line 147, in <module>
b.attach_kprobe(event="blk_account_io_done",
File "/usr/lib/python3/dist-packages/bcc/__init__.py", line 683, in attach_kprobe
raise Exception("Failed to attach BPF program %s to kprobe %s" %
Exception: Failed to attach BPF program b'trace_req_done' to kprobe b'blk_account_io_done'
🔍 可能原因与解决方案
内核版本和内核符号名不匹配
blk_account_io_done是一个内核函数名,biolatency工具需要在内核中找到这个符号并附加探针。 如果你的内核版本和BCC工具设计时预期的内核版本差异较大,或者内核配置不支持该探针,可能会找不到该符号或参数不兼容。缺少内核调试符号
某些内核模块或内核缺少调试符号,导致探针无法正确附加。
内核安全限制(比如禁止
kprobe)某些发行版或者内核配置为了安全,可能禁止
kprobe或限制BPF程序附加。
具体排查建议
- 确认内核版本
1
$ uname -r
确认是否为主流支持版本(如5.x或6.x系列)。如果是较新内核,可能BCC的旧版工具存在兼容问题。
- 查看内核符号
1
$ sudo cat /proc/kallsyms | grep blk_account_io_done
如果没有输出,说明内核中没有导出该符号,kprobe就无法附加。
- 升级
BCC和内核头文件
确保BCC和内核头文件版本匹配,并且是最新版本。
1
2
$ sudo apt update
$ sudo apt upgrade bpfcc-tools linux-headers-$(uname -r)
- 尝试使用
bpftrace版本
bpftrace有时能更好兼容新内核:
1
$ sudo bpftrace -e 'kprobe:blk_account_io_done { @[comm] = hist(nsecs / 1000); }'
🌲 BPF跟踪的可见性
BPF跟踪提供了对整个软件栈的可观测性,并允许你按需创建新的工具和监控手段。你可以直接在生产环境中使用BPF跟踪,无需重启系统,也无需以特殊模式重启应用程序。
这就像拥有了“X光视野”:当你需要深入查看某个内核组件、设备或应用程序库时,BPF让你能够以前所未有的方式进行实时、在线的观察。
为了说明这一点,图1-2展示了一个通用系统软件栈的结构,我在其上标注了可用于观察各个组件的基于BPF的性能分析工具。这些工具来自BCC、bpftrace以及本书的内容,其中很多将在后续章节中详细介绍。
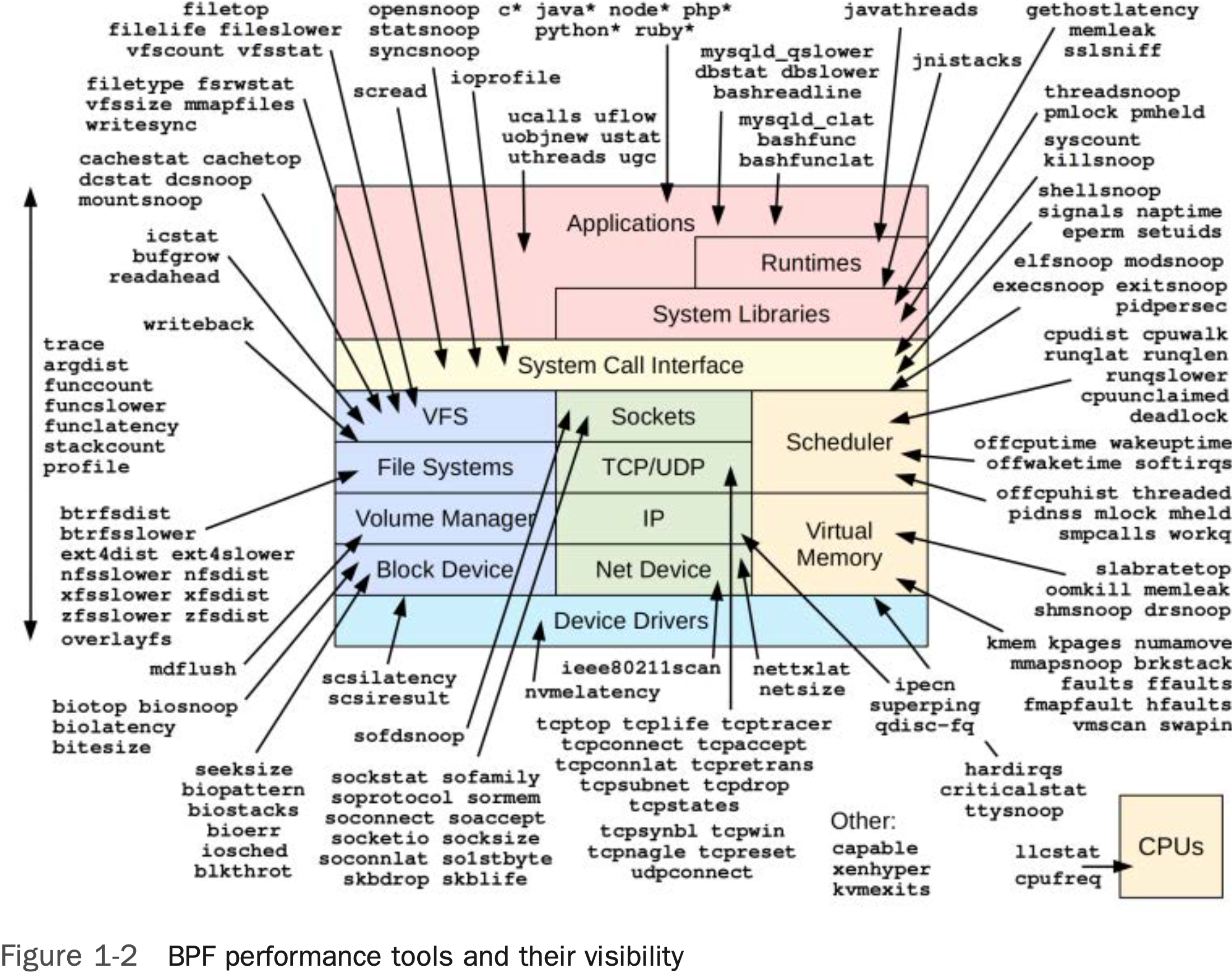
想想看,你通常会使用哪些工具来分析诸如内核的CPU调度器、虚拟内存、文件系统等组件。只需浏览这张图,你或许就能发现过去难以观察的“盲区”,而现在可以通过BPF工具来获取可见性。
这些传统工具及其对不同组件的观测能力在表1-1中进行了总结,并标明了BPF跟踪是否也能用于这些组件的分析。传统工具仍然是性能分析的良好起点,你可以先用它们进行初步调查,然后再借助BPF跟踪工具深入探索。
表1-1:传统分析工具
Components | Traditional Analysis Tools | BPF Tracing |
|---|---|---|
Applications with language runtimes: Java, Node.js, Ruby, PHP | Runtime debuggers | Yes, with runtime support |
Applications using compiled code: C, C++, Golang | System debuggers | Yes |
System libraries: /lib/* | ltrace(1) | Yes |
System call interface | strace(1), perf(1) | Yes |
Kernel: Scheduler, file systems, TCP , IP , etc | Ftrace, perf(1) for sampling | Yes, in more detail |
Hardware: CPU internals, devices | perf, sar, /proc counters | Yes, direct or indirect |
🌲 动态插桩:kprobes和uprobes
BPF跟踪支持多种事件来源,从而实现对整个软件栈的可观测性。其中值得特别提及的是动态插桩(也称为动态跟踪):即在运行中的软件上动态插入观测点的能力,甚至可以直接在生产环境中完成。这种方式在不使用时不会带来任何运行开销,因为软件本身无需修改。BPF工具常常使用这种方式对内核函数和用户应用函数的起始和结束位置进行插桩——这些函数在一个典型的软件栈中往往成千上万。借助这种技术,获取的可见性之深与全面,几乎可以说是一种“超能力”。
动态插桩技术最早出现在1990年代[Hollingsworth 94],灵感来自调试器通过在指令地址处插入断点的技术。与调试器不同的是,动态插桩允许目标软件在记录必要信息后自动继续执行,而不是交给交互式调试器接管。当时也出现了配套的动态跟踪工具(如kerninst [Tamches 99]),并配有专用的跟踪语言,但这些工具始终较为冷门、使用率低。其中一个原因是风险较高:动态跟踪会在运行时修改进程或内核的指令,一旦出错,可能会立即导致内存损坏或程序/内核崩溃。
Linux上的动态插桩最早由IBM团队在2000年开发,名为DProbes,但该补丁集被内核社区拒绝采纳。直到2004年,Linux才正式引入基于DProbes的内核函数动态插桩机制——kprobes。不过此时的kprobes依然名气不大,使用也比较复杂。
真正的转折点发生在2005年,Sun Microsystems推出了自己的动态跟踪系统DTrace,配套有易用的D语言,并将其集成进 Solaris 10操作系统。Solaris一直以生产环境的稳定性著称,而DTrace作为默认软件包随系统发布,向业界证明了动态跟踪在生产环境中是可行且安全的。这一事件成为该技术发展的里程碑。我本人也发表了大量介绍DTrace的文章,构建并发布了许多DTrace工具。Sun的市场、销售和教育部门都积极推广这项技术,甚至将DTrace纳入Solaris的标准培训课程。这些努力促使动态插桩从小众技术一跃成为被广泛认可且备受关注的能力。
Linux在2012年加入了用户态函数的动态插桩机制,称为uprobes。BPF跟踪工具现已支持使用kprobes和uprobes对整个软件栈进行动态插桩。
为了更直观地展示动态跟踪的用法,表1-2给出了几个使用bpftrace指定探针的例子,这些探针基于kprobes和uprobes。
表1-2:bpftrace中kprobe和uprobe示例
| 探针 | 描述 |
|---|---|
kprobe:vfs_read | 插桩内核函数vfs_read()的开始位置 |
kretprobe:vfs_read | 插桩内核函数vfs_read()的返回点 |
uprobe:/bin/bash:readline | 插桩/bin/bash中readline()函数的开始位置 |
uretprobe:/bin/bash:readline | 插桩/bin/bash中readline()函数的返回点 |
🌲 静态插桩:Tracepoints与USDT
动态插桩虽然强大,但也存在一些缺点:它依赖的函数可能在不同版本的软件中被重命名或移除,这就是所谓的“接口稳定性问题”。一旦你升级了内核或应用程序,可能会发现原本可用的BPF工具突然无法正常工作——要么报错无法找到函数进行插桩,要么干脆没有任何输出。另一个问题是:出于优化目的,编译器可能会将函数内联(inline),这样就无法再通过kprobes或uprobes对这些函数进行插桩。
为了解决上述接口不稳定和函数内联的问题,静态插桩成为了一个更可靠的方案。它通过在软件中嵌入稳定的事件名,由开发者负责维护。BPF跟踪支持内核静态插桩(tracepoints)和用户态静态插桩(USDT,User-level Statically Defined Tracing)。不过,静态插桩的缺点是增加了开发者的维护负担,因此大多数软件只提供有限数量的静态插桩点。
如果你打算开发自己的BPF工具,这些细节才是你需要关心的。建议的策略是:优先尝试使用静态插桩(tracepoints 和 USDT),只有在无法满足需求时再考虑使用动态插桩(kprobes和uprobes)。
下表展示了bpftrace中使用tracepoints和USDT进行静态插桩的示例:
表 1-3:bpftrace的tracepoint和USDT示例
| 探针类型与名称 | 描述 |
|---|---|
tracepoint:syscalls:sys_enter_open | 插桩open(2)系统调用 |
usdt:/usr/sbin/mysqld:mysql:query__start | 插桩/usr/sbin/mysqld中的query__start探针 |
🔍 本质区别一:插桩时机不同
| 类型 | 插桩时机 | 说明 |
|---|---|---|
| 静态插桩 | 开发阶段,写在源代码或汇编中 | 由程序员或编译器在编译时或链接时就明确插好 |
| 动态插桩 | 运行时(Run-time) | 在程序运行期间动态地修改指令或内存以添加探针 |
🧠 本质区别二:是否需要修改程序本体
| 类型 | 是否修改原程序 | 稳定性 | 灵活性 |
|---|---|---|---|
| 静态插桩 | 是,插桩写死在程序里 | 高:接口稳定、兼容升级 | 低:不容易修改或扩展 |
| 动态插桩 | 否,运行时插入,程序本体不变 | 低:接口不稳定,升级后可能失效 | 高:可根据需求动态添加/移除 |
🌲 初识bpftrace:跟踪open()
我们来写一个简单的bpftrace程序,用于跟踪open(2)系统调用。内核已经为其提供了一个tracepoint(syscalls:sys_enter_open),我们可以直接在命令行执行:
1
# bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
你现在不需要理解这一行代码的具体含义,bpftrace的语法与安装将在第5章详细介绍。不过,即使不了解语法,也许你能大致猜到这个程序的作用——这说明语言本身是直观且易用的。现在请你专注于输出结果:
1
2
3
4
5
6
Attaching 1 probe...
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
slack /run/user/1000/gdm/Xauthority
^C
输出结果显示了调用open(2)系统调用的进程名(如slack),以及其尝试打开的文件路径。因为bpftrace是系统范围内跟踪,所以任何调用open(2)的进程都会被记录。每一行表示一个系统调用事件,是典型的“每事件一行”风格的工具。
BPF跟踪不仅适用于服务器分析,我写这本书时就在笔记本上运行它,看到的是Slack聊天程序正在打开的文件。
这个小程序定义在单引号中的一行内,按下回车后即被编译执行。bpftrace会激活open(2)的tracepoint;当你按下Ctrl-C停止程序时,该tracepoint会被卸载,小程序也随之被移除。这就是BPF跟踪工具按需启用的方式:工具只在命令运行期间处于激活状态,可以短至几秒。
不过,这次的输出比我预期的少,可能有些open(2)调用没被跟踪到。内核中其实还有多个open变体,我刚才只跟踪了其中一个。我们可以通过通配符列出所有相关tracepoints:
1
2
3
4
# bpftrace -l 'tracepoint:syscalls:sys_enter_open*'
tracepoint:syscalls:sys_enter_open_by_handle_at
tracepoint:syscalls:sys_enter_open
tracepoint:syscalls:sys_enter_openat
现在看来,现代系统中更多使用的是openat(2)。我用另一个bpftrace一行式来确认:
1
2
3
4
5
# bpftrace -e 'tracepoint:syscalls:sys_enter_open* { @[probe] = count(); }'
Attaching 3 probes...
^C
@[tracepoint:syscalls:sys_enter_open]: 5
@[tracepoint:syscalls:sys_enter_openat]: 308
虽然这段代码的具体机制我们会在第5章再讲,但你现在只需看懂输出结果:它统计了每个tracepoint的调用次数。结果说明:在这段跟踪期间,openat(2)被调用了308次,而open(2)仅有5次。这些计数都是由内核中的BPF程序高效完成的。
如果我想同时追踪open(2)和openat(2),可以把两个tracepoint都加进一行式代码中。但这样命令会变得冗长,不如直接写成脚本保存下来,方便编辑。事实上,bpftrace已经为你准备好了这样的工具脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# opensnoop.bt
Attaching 3 probes...
Tracing open syscalls... Hit Ctrl-C to end.
PID COMM FD ERR PATH
2440 snmp-pass 4 0 /proc/cpuinfo
2440 snmp-pass 4 0 /proc/stat
25706 ls 3 0 /etc/ld.so.cache
25706 ls 3 0 /lib/x86_64-linux-gnu/libselinux.so.1
25706 ls 3 0 /lib/x86_64-linux-gnu/libc.so.6
25706 ls 3 0 /lib/x86_64-linux-gnu/libpcre.so.3
25706 ls 3 0 /lib/x86_64-linux-gnu/libdl.so.2
25706 ls 3 0 /lib/x86_64-linux-gnu/libpthread.so.0
25706 ls 3 0 /proc/filesystems
25706 ls 3 0 /usr/lib/locale/locale-archive
25706 ls 3 0 .
1744 snmpd 8 0 /proc/net/dev
1744 snmpd -1 2 /sys/class/net/lo/device/vendor
2440 snmp-pass 4 0 /proc/cpuinfo
^C
该输出以列形式展示:进程ID(PID)、命令名(COMM)、文件描述符(FD)、错误码(ERR)、文件路径(PATH)。opensnoop.bt可用于:
- 排查程序为什么无法打开文件(例如路径错误);
- 查找配置文件或日志文件的实际路径;
- 发现性能问题,比如文件被过于频繁地打开,或者反复查找错误位置。
这是一个非常实用的工具。
bpftrace自带了20多个类似的现成工具,而BCC提供的工具数量超过70个。除了能直接帮你解决问题,这些工具的源码也展示了如何追踪不同目标。就像刚才追踪open(2)时遇到的问题,它们的源码往往也包含了解决方案。
回到BCC:追踪open()
现在我们来看看使用BCC实现的opensnoop(8)工具:
1
2
3
4
5
6
7
8
9
10
# opensnoop
PID COMM FD ERR PATH
2262 DNS Res~er #657 22 0 /etc/hosts
2262 DNS Res~er #654 178 0 /etc/hosts
29588 device poll 4 0 /dev/bus/usb
29588 device poll 6 0 /dev/bus/usb/004
29588 device poll 7 0 /dev/bus/usb/004/001
29588 device poll 6 0 /dev/bus/usb/003
^C
#
这个输出看起来和前面使用bpftrace的单行脚本输出非常相似——至少列名是一样的。但这个opensnoop(8)输出相比bpftrace的版本有一个优势:它支持命令行参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# opensnoop -h
usage: opensnoop [-h] [-T] [-x] [-p PID] [-t TID] [-d DURATION] [-n NAME]
[-e] [-f FLAG_FILTER]
Trace open() syscalls
可选参数:
-h, --help 显示帮助信息并退出
-T, --timestamp 输出中包含时间戳
-x, --failed 只显示失败的 open 调用
-p PID, --pid PID 只追踪指定的进程 PID
-t TID, --tid TID 只追踪指定的线程 TID
-d DURATION, --duration 指定追踪的总时长(秒)
-n NAME, --name NAME 只显示进程名中包含该字符串的项
-e, --extended_fields 显示扩展字段
-f FLAG_FILTER, --flag_filter FLAG_FILTER
根据open()的flags参数过滤(如O_WRONLY)
示例:
./opensnoop # 追踪所有open()系统调用
./opensnoop -T # 输出中包含时间戳
./opensnoop -x # 只显示失败的open调用
./opensnoop -p 181 # 只追踪进程PID为181的进程
./opensnoop -t 123 # 只追踪线程TID为123的线程
./opensnoop -d 10 # 只追踪10秒
./opensnoop -n main # 只显示进程名包含"main"的条目
./opensnoop -e # 显示扩展字段
./opensnoop -f O_WRONLY -f O_RDWR # 只显示具有写操作的调用
bpftrace工具通常设计得简单同时专注于单一用途,而BCC工具通常更复杂,支持多种运行模式。例如,你可以通过修改 bpftrace脚本让它只显示失败的open调用,但BCC版本已经内建了这个选项(-x):
1
2
3
4
5
6
7
8
9
10
11
# opensnoop -x
PID COMM FD ERR PATH
991 irqbalance -1 2 /proc/irq/133/smp_affinity
991 irqbalance -1 2 /proc/irq/141/smp_affinity
991 irqbalance -1 2 /proc/irq/131/smp_affinity
991 irqbalance -1 2 /proc/irq/138/smp_affinity
991 irqbalance -1 2 /proc/irq/18/smp_affinity
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
20543 systemd-resolve -1 2 /run/systemd/netif/links/5
[...]
这个输出显示了多个重复的失败调用。这种模式可能表明存在效率低下或配置错误的问题,需要进一步排查。
BCC工具通常提供多种选项来调整其行为,这让它们比bpftrace工具更加灵活。因此,BCC工具是一个很好的起点:如果你能用现成的BCC工具解决问题,就无需编写任何BPF代码。
不过,如果它们无法满足你的可见性需求,你可以切换到bpftrace,自行开发定制工具——因为bpftrace语言更简单,开发门槛更低。
当然,bpftrace工具之后也可以被改写成支持丰富选项的BCC工具,就像上面的opensnoop(8)一样。此外,BCC工具还能根据可用情况选择使用不同的事件源:如使用tracepoints(如果可用),否则使用kprobes。
但要注意,BCC编程更复杂,超出了本书的范围;本书聚焦于bpftrace的使用。
🌲 小结
BPF追踪工具广泛用于性能分析和故障排查,目前有两个主要项目提供这些工具:BCC和bpftrace。本章介绍了扩展BPF(eBPF)、BCC、bpftrace,以及它们使用的动态与静态插桩技术。