技术背景【第二章】
第1章介绍了BPF性能工具所涉及的各种技术,而本章将对它们进行更深入的讲解,包括它们的历史、接口、内部机制,以及与BPF的结合使用。
本章是全书中技术深度最高的一章。为了简洁起见,内容默认你已具备一定的内核内部结构和指令级编程方面的知识。
本章的学习目标并不是要你死记硬背每一页内容,而是希望你能够:
- 理解
BPF的起源,以及扩展BPF(eBPF)在今天的作用; - 掌握栈帧指针遍历(
frame pointer stack walking)等常用技术; - 理解火焰图(
flame graph)的构成与分析方法; - 掌握
kprobe和uprobe的用法,及其稳定性相关的注意事项; - 理解
tracepoint、USDT探针和动态USDT的角色; - 了解性能监控计数器(
PMC)以及它们如何结合BPF使用; - 掌握一些面向未来的发展方向:如
BTF以及其它BPF栈遍历器。
理解本章将帮助你更深入地掌握本书后续内容。但如果你此刻只是想快速上手BPF工具来解决实际问题,也可以先略读本章,待需要时再回来深入学习。
第3章将正式带你开始使用BPF工具,寻找系统中的性能优化机会。
🌲 BPF技术关系图
图2-1展示了本章涉及的多项BPF相关技术及它们之间的关系。
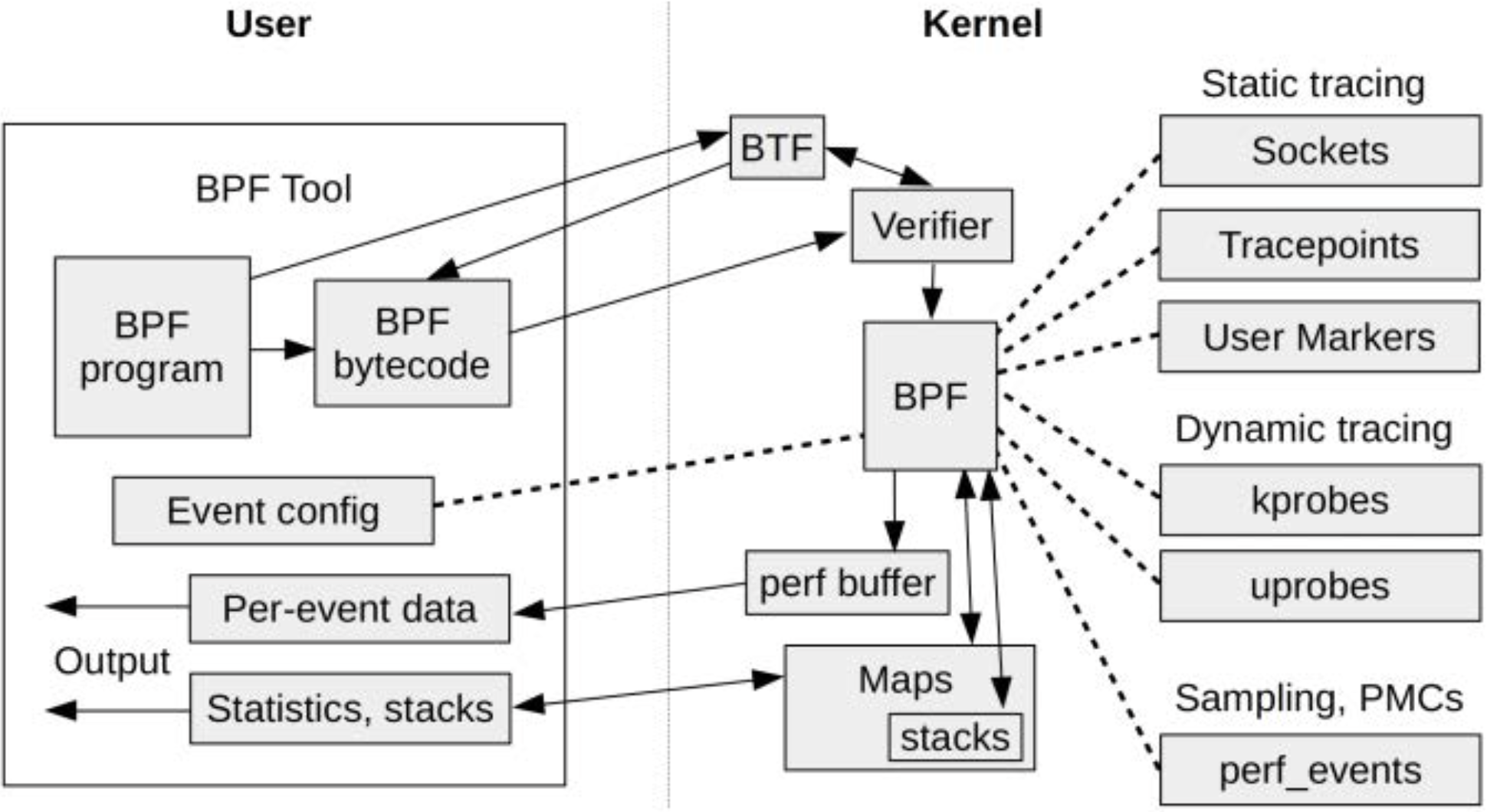
🌲 BPF
BPF(Berkeley Packet Filter)最初是在BSD操作系统上开发的,首次发表于1992年的论文《The BSD Packet Filter: A New Architecture for User-level Packet Capture》[McCanne 92]。该论文在1993年美国圣地亚哥召开的USENIX冬季会议上发表,同期还有《Measurement, Analysis, and Improvement of UDP/IP Throughput for the DECstation 5000》。虽然DECstation早已成为历史,但BPF却得以延续,并成为业界标准的包过滤解决方案。
BPF的工作原理非常有趣:用户通过定义一段针对BPF虚拟机的指令集(通常称为BPF字节码)来描述过滤逻辑,然后将这段指令传递给内核,由内核中的解释器执行。这样一来,包过滤的过程可以直接在内核态完成,避免了将每个数据包拷贝到用户空间的高昂开销,从而极大提升了像tcpdump(8)这样的工具的性能。
更重要的是,这种机制也具备了安全性:来自用户空间的BPF程序可以在执行前被内核验证为“安全”。因为早期的包过滤需要在内核中完成,因此安全性是一项硬性要求。
图2-2展示了这一工作机制的流程。
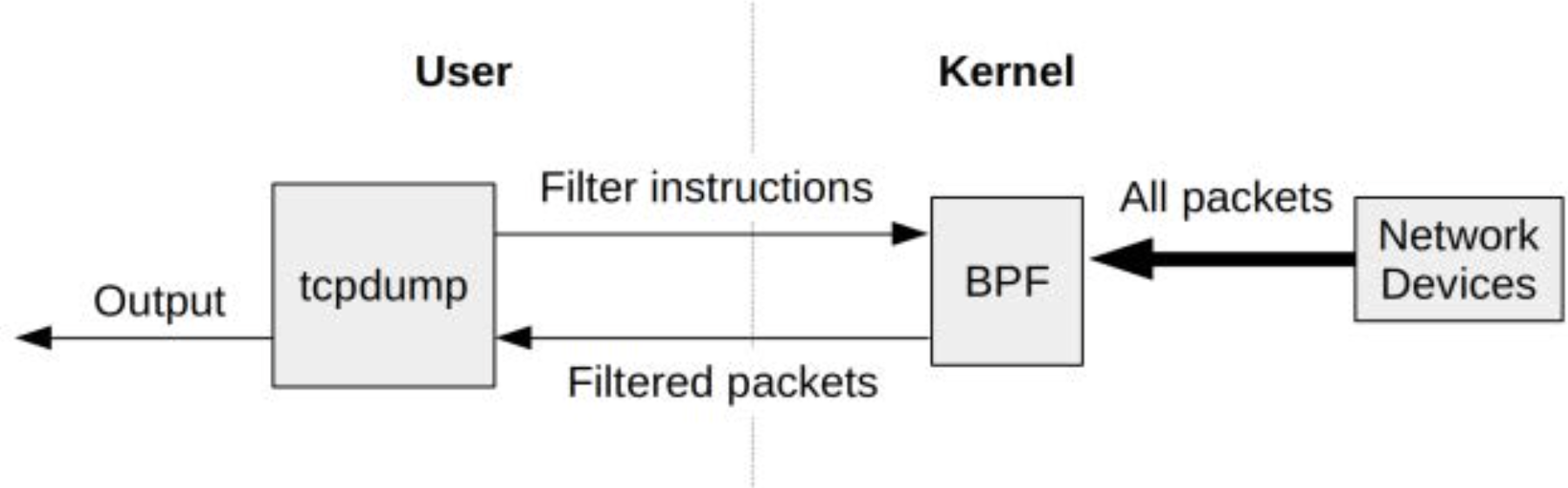
你可以使用tcpdump(8)的-d选项来打印其使用的BPF指令,以查看它是如何处理过滤表达式的。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
$ tcpdump -d host 127.0.0.1 and port 80
Warning: assuming Ethernet
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 18
(002) ld [26]
(003) jeq #0x7f000001 jt 6 jf 4
(004) ld [30]
(005) jeq #0x7f000001 jt 6 jf 18
(006) ldb [23]
(007) jeq #0x84 jt 10 jf 8
(008) jeq #0x6 jt 10 jf 9
(009) jeq #0x11 jt 10 jf 18
(010) ldh [20]
(011) jset #0x1fff jt 18 jf 12
(012) ldxb 4*([14]&0xf)
(013) ldh [x + 14]
(014) jeq #0x50 jt 17 jf 15
(015) ldh [x + 16]
(016) jeq #0x50 jt 17 jf 18
(017) ret #262144
(018) ret #0
原始的BPF(现在通常称为“经典BPF”)是一个功能受限的虚拟机。它只有两个寄存器、一个由16个内存槽组成的临时内存区域(scratch memory)和一个程序计数器(PC)。这些寄存器全都基于32位操作。经典BPF于1997年被引入Linux内核,从 2.1.75版本开始。
随着BPF被集成进Linux内核,它逐步得到了多个重要的改进:
- 2011年7月,
Eric Dumazet在Linux 3.0中加入了BPF的即时编译器(JIT),使其相较于解释执行获得了性能提升。 - 2012年,
Will Drewry将BPF应用于seccomp(安全计算)系统调用策略中,这标志着BPF首次被用于网络以外的场景,并展示了它作为通用执行引擎的潜力。
🌲 扩展BPF(eBPF)
扩展BPF(eBPF)最初由Alexei Starovoitov在PLUMgrid工作期间提出,当时该公司正在探索构建软件定义网络(SDN)的新方式。这项提议是对BPF近20年来的第一次重大更新,目标是将BPF扩展为一个通用虚拟机。
当该提案尚处于草案阶段时,来自Red Hat的内核开发者Daniel Borkmann协助对其进行了重构,使其能被接受进入内核主线,作为现有BPF的替代实现。这一扩展BPF版本最终被成功并入主线,并随后得到了众多开发者的贡献。
eBPF的关键改进包括:
- 增加了更多寄存器;
- 将字长从32位提升到64位;
- 引入了灵活的
BPF“映射”(map)机制用于数据存储; - 允许调用部分受限的内核函数;
JIT编译器可将eBPF程序一一映射为本地指令和寄存器,从而复用原本为原生代码优化的技术;- 同时,
BPF校验器(verifier)也得到了增强,以支持这些扩展并拒绝任何不安全的代码。
表2-1展示了经典BPF与扩展BPF之间的主要差异。
| Factor | Classic BPF | Extended BPF |
|---|---|---|
| Register count | 2: A, X | 10: R0–R9, plus R10 as a read-only frame pointer |
| Register width | 32-bit | 64-bit |
| Storage | 16 memory slots: M[0–15] | 512 bytes of stack space, plus infinite “map” storage |
| Restricted kernel calls | Very limited, JIT specific | Yes, via the bpf_call instruction |
| Event targets | Packets, seccomp-BPF | Packets, kernel functions, user functions, tracepoints, user markers, PMCs |
Alexei最初的补丁集发布于2013年9月,标题为“extended BPF”。到2013年12月,他已开始提议将其用于追踪过滤器。经过与Daniel的反复讨论与开发,这些补丁从2014年3月开始合并进Linux主线内核。
JIT相关组件合并于Linux 3.15(2014年6月发布);- 控制
BPF的系统调用bpf(2)合并于Linux 3.18(2014年12月发布); - 在后续的
Linux 4.x系列中,BPF又陆续加入了对kprobes、uprobes、tracepoints和perf_events的支持。
在最初的补丁集中,这项技术曾被简称为eBPF,但Alexei后来统一称之为BPF。目前在net-dev邮件列表中,所有BPF相关开发也都以“BPF”来称呼它。
Linux中BPF运行时的架构如图2-3所示。BPF程序在执行前会经过BPF 校验器(verifier)的检查,之后再由BPF虚拟机执行。BPF虚拟机本身既可以解释执行,也可以使用JIT编译器将其转为本地指令直接运行。
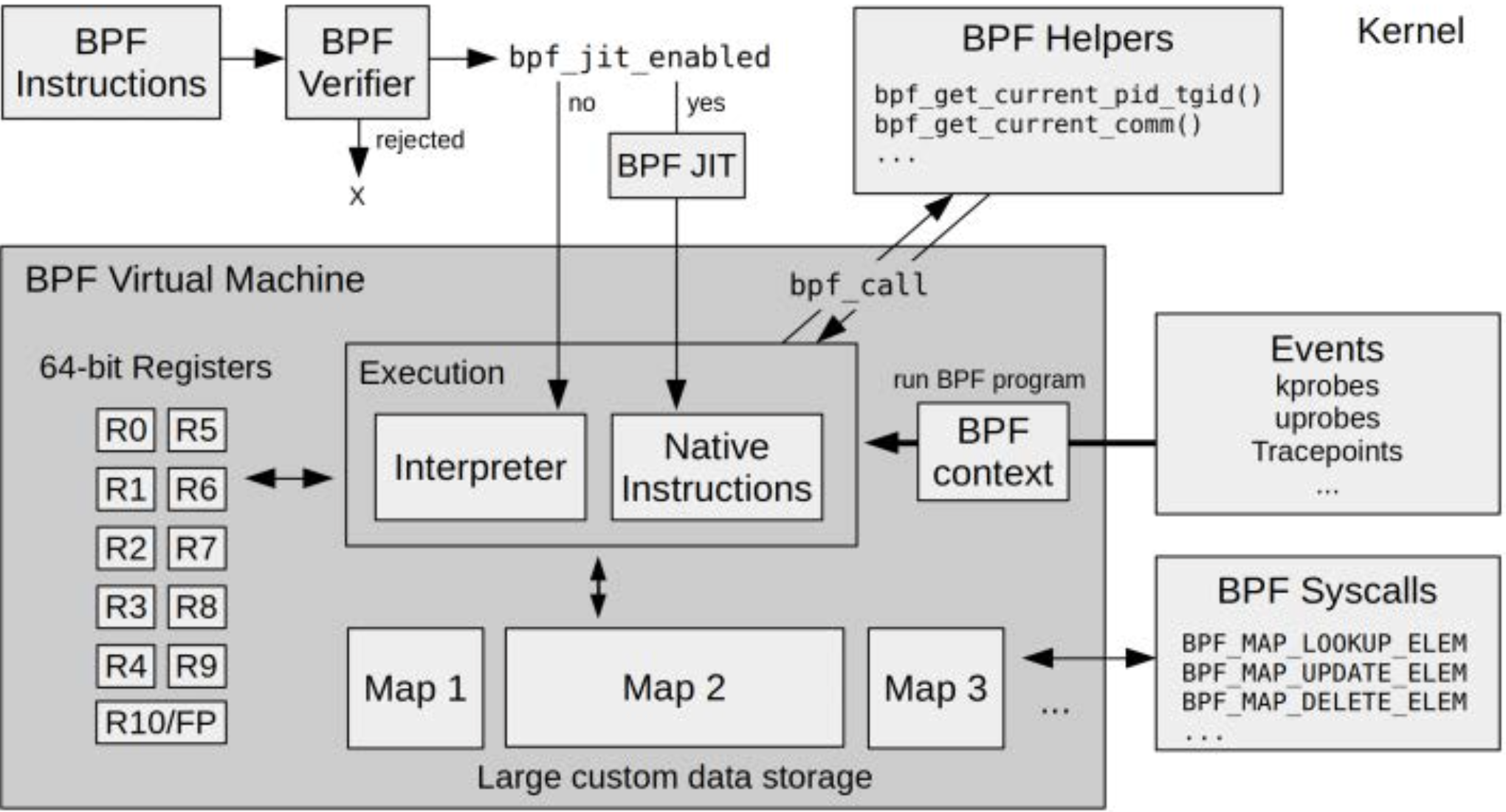
校验器的一个重要职责是拒绝不安全的操作(如无限循环),因为BPF程序必须在有限时间内完成执行。此外,BPF还能通过helper函数访问内核状态,并使用BPF map进行状态存储。
BPF程序的执行通常是由某些事件触发的,例如:
kprobes(内核函数入口/出口)uprobes(用户空间函数入口/出口)tracepoints(内核预定义埋点)
接下来的小节将介绍:
- 性能工具为什么需要
BPF; eBPF编程的方式;- 如何查看
BPF指令; BPF的API;BPF的限制;- 以及
BTF(BPF Type Format)的作用。
这些内容为理解bpftrace与BCC在背后是如何运作的奠定基础。
🍃 为什么性能分析工具需要BPF
性能分析工具之所以使用扩展BPF(eBPF),部分原因在于其可编程性。借助BPF程序,可以执行自定义的延迟计算和统计汇总。这些特性本身就足以打造一个非常强大的工具,事实上,许多现有的跟踪工具也具备类似功能。
但BPF的独特之处在于:它不仅功能强大,还具有高效性与生产环境的安全性,而且是内建于Linux内核之中的。这意味着我们可以在生产系统中直接运行这些工具,而无需引入额外的内核模块或组件。
下面我们通过一个输出示例和示意图,了解性能工具是如何利用BPF的。这个例子来自我早期发布的一个BPF工具——bitehist,它将磁盘I/O的数据大小以直方图形式展示。
1
2
3
4
5
6
7
8
9
10
11
# bitehist
Tracing block device I/O... Interval 5 secs. Ctrl-C to end.
kbytes : count distribution
0 -> 1 : 3 | |
2 -> 3 : 0 | |
4 -> 7 : 3395 |************************************* |
8 -> 15 : 1 | |
16 -> 31 : 2 | |
32 -> 63 : 738 |******* |
64 -> 127 : 3 | |
128 -> 255 : 1 | |
图2-4展示了BPF是如何提升该工具效率的。
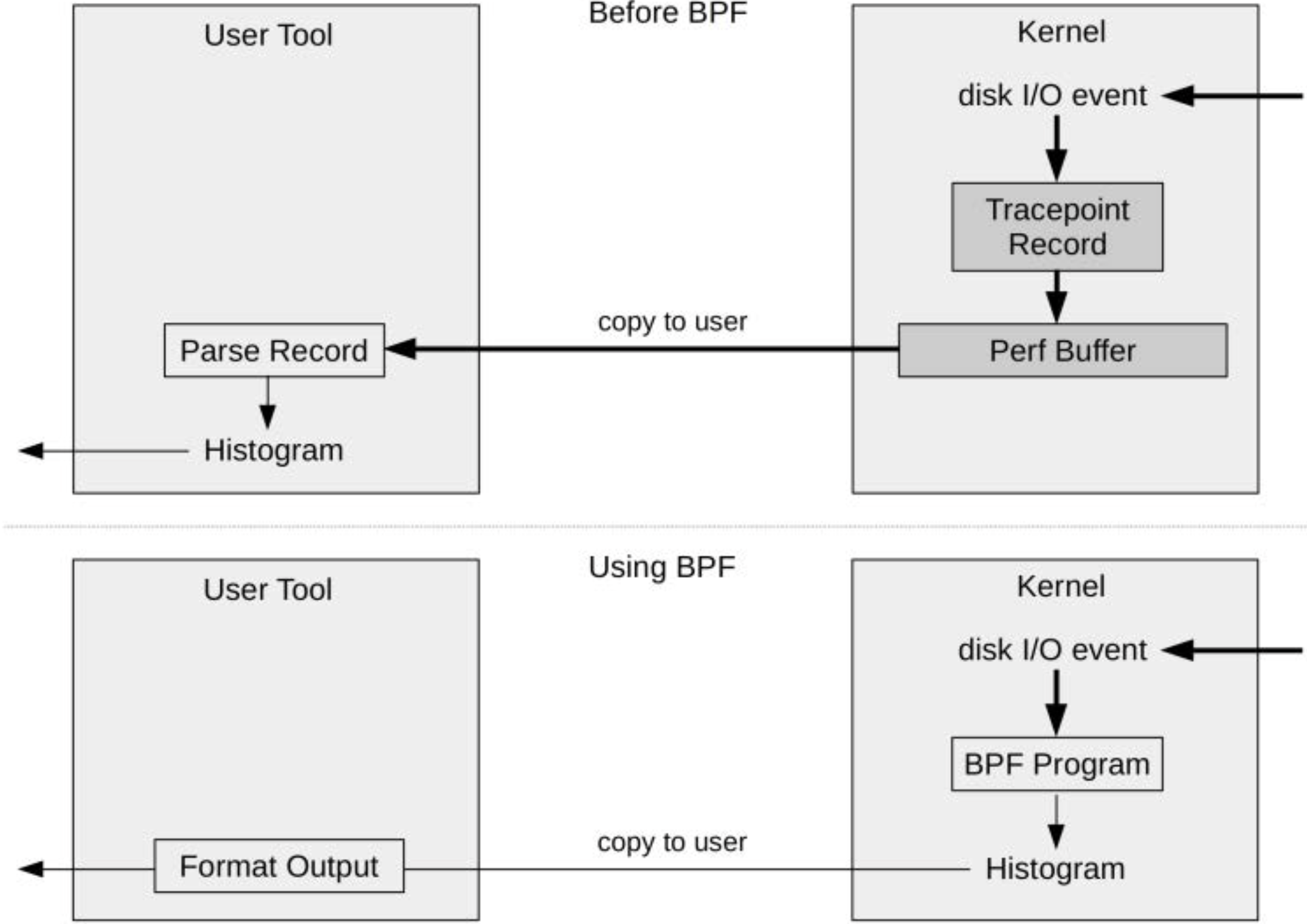
图2-4使用BPF前后的直方图生成方式对比
关键的改变在于:这个直方图是在内核上下文中生成的,从而大大减少了需要复制到用户态的数据量。这种效率的提升非常显著,使得原本因代价过高无法在生产中使用的工具变得可行。
在使用BPF之前,生成这样的直方图需要以下步骤:
- 在内核中:启用对磁盘
I/O事件的观测(instrumentation)。 - 每次事件发生时:向
perf缓冲区写入一条记录。如果使用tracepoint(推荐的方式),记录会包含多个字段的元数据。 - 在用户空间:定期将整个
perf缓冲区复制到用户空间。 - 在用户空间:遍历所有事件,只解析其中的
bytes字段,其它字段会被忽略。 - 在用户空间:对
bytes字段生成直方图汇总。
对于I/O压力较大的系统来说,第2至第4步会带来较高的性能开销。设想每秒传输10,000条磁盘I/O跟踪记录到用户空间并逐条解析,开销是极其巨大的。
使用BPF后的优化流程:
- 在内核中:启用磁盘
I/O事件,并附加一个由bitesize定义的自定义BPF程序。 - 每次事件发生时:
BPF程序在内核中运行,仅提取bytes字段,并将其写入自定义的BPF映射(map)作为直方图数据结构。 - 在用户空间:只需一次性读取
BPF映射中的直方图数据并输出即可。
这种方法完全避免了将事件逐条复制到用户空间并重新处理的高昂代价。同时,也避免了复制那些不被使用的元数据字段。最终,唯一复制到用户空间的数据就是直方图中的“计数列”(count column),即一组数字数组,这就是我们在工具输出中看到的内容。
🍃 BPF与内核模块的对比
理解BPF在可观测性(observability)方面的优势,还有一种方法是将它与内核模块进行对比。事实上,kprobes和tracepoints早已在内核中存在多年,它们可以直接通过可加载内核模块(LKM)来使用。但相比之下,BPF在追踪分析中的优势包括:
安全性更高:
BPF程序会经过verifier验证器的检查,而内核模块可能引入内核崩溃(kernel panic)或安全漏洞。支持丰富的数据结构:
BPF提供了结构化的map数据结构,便于存储与传递观测数据。良好的可移植性:
BPF程序可以一次编译,到处运行。因为BPF的指令集、map、helper函数和运行环境构成了一个稳定的ABI(应用二进制接口)。(不过,需要注意的是,有些
BPF跟踪程序仍依赖于不稳定的部分,比如基于内核结构体的kprobe,第2.3.10节会介绍相关解决方案。)无需依赖内核源码或构建产物:
BPF程序编译时不需要内核构建环境,降低了使用门槛。学习成本低:
BPF编程比编写内核模块更容易掌握,不需要深厚的内核开发经验,因此对更多开发者友好。
此外,BPF在网络方面还具备更多优势,比如支持原子性替换(atomic replacement)BPF程序。相比之下,内核模块想要升级代码,需要先卸载旧模块再重新加载新模块,这个过程可能会中断服务。
当然,内核模块的一个优势在于它能访问其他内核函数与功能,不受限于BPF helper调用。但这种灵活性也伴随着风险:如果调用了不当的内核函数,容易引入系统级别的bug。
🍃 编写BPF程序
BPF支持多种前端工具来进行编程。针对追踪用途,常见的从低到高层次的编程方式包括:
LLVMBCCbpftrace
LLVM编译器支持将程序编译为BPF指令。开发者可以使用LLVM支持的高级语言(如C,通过Clang编译)或LLVM中间表示(IR)来编写BPF程序,然后编译生成BPF字节码。LLVM编译器还带有优化器,可提升生成的BPF程序的效率和紧凑性。
尽管直接用LLVM IR编写BPF程序已经是一种进步,但更推荐使用更高级的工具如BCC或bpftrace:
BCC允许使用C语言来编写BPF程序;bpftrace则提供了一种专用的高级脚本语言。
这两者在内部仍然依赖LLVM IR及其编译库将代码编译为BPF字节码。
本书所介绍的性能分析工具,主要基于BCC和bpftrace开发。直接使用BPF指令或LLVM IR进行编程,一般是BCC和bpftrace开发者的工作范畴,超出了本书的讨论范围。 对于我们这些使用和开发BPF性能工具的人而言,了解底层BPF指令并非必要。
不过,如果你想深入成为BPF字节码开发者,或对底层实现感兴趣,可以参考以下资料:
- 附录
E简要介绍了BPF的指令集和宏。 Linux内核源码树中的文档Documentation/networking/filter.txt提供了BPF指令的详细说明。LLVM IR可通过LLVM官网的llvm::IRBuilderBase类参考文档 进行学习。Cilium的BPF与XDP参考指南也提供了丰富的实践资料。
尽管我们大多数人不会直接编写BPF指令,但在排查工具问题时,我们常常会查看这些底层内容。接下来的两个小节将展示如何使用bpftool(8)和bpftrace来查看和调试BPF程序。
🍃 查看BPF指令:bpftool
bpftool(8)是从Linux 4.15开始引入的工具,用于查看和操作BPF对象,包括程序(program)和映射(map)。该工具的源码位于Linux内核源码树的tools/bpf/bpftool目录下。
本节将简要介绍如何使用bpftool(8)来查找已加载的BPF程序并打印其指令内容。
运行bpftool命令后,如果不带参数,它会显示它所支持操作的对象类型。从Linux 5.2起,其默认输出如下:
1
2
3
4
5
6
7
8
$ bpftool
Usage: bpftool [OPTIONS] OBJECT { COMMAND | help }
bpftool batch file FILE
bpftool version
OBJECT := { prog | map | link | cgroup | perf | net | feature | btf | gen | struct_ops | iter }
OPTIONS := { {-j|--json} [{-p|--pretty}] | {-d|--debug} |
{-V|--version} }
每种对象类型都有独立的帮助页面。例如,针对BPF程序的帮助信息,可以通过以下方式查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
$ bpftool prog help
Usage: bpftool prog { show | list } [PROG]
bpftool prog dump xlated PROG [{ file FILE | [opcodes] [linum] [visual] }]
bpftool prog dump jited PROG [{ file FILE | [opcodes] [linum] }]
bpftool prog pin PROG FILE
bpftool prog { load | loadall } OBJ PATH \
[type TYPE] [{ offload_dev | xdpmeta_dev } NAME] \
[map { idx IDX | name NAME } MAP]\
[pinmaps MAP_DIR]
[autoattach]
bpftool prog attach PROG ATTACH_TYPE [MAP]
bpftool prog detach PROG ATTACH_TYPE [MAP]
bpftool prog run PROG \
data_in FILE \
[data_out FILE [data_size_out L]] \
[ctx_in FILE [ctx_out FILE [ctx_size_out M]]] \
[repeat N]
bpftool prog profile PROG [duration DURATION] METRICs
bpftool prog tracelog
bpftool prog help
MAP := { id MAP_ID | pinned FILE | name MAP_NAME }
PROG := { id PROG_ID | pinned FILE | tag PROG_TAG | name PROG_NAME }
TYPE := { socket | kprobe | kretprobe | classifier | action |
tracepoint | raw_tracepoint | xdp | perf_event | cgroup/skb |
cgroup/sock | cgroup/dev | lwt_in | lwt_out | lwt_xmit |
lwt_seg6local | sockops | sk_skb | sk_msg | lirc_mode2 |
sk_reuseport | flow_dissector | cgroup/sysctl |
cgroup/bind4 | cgroup/bind6 | cgroup/post_bind4 |
cgroup/post_bind6 | cgroup/connect4 | cgroup/connect6 |
cgroup/connect_unix | cgroup/getpeername4 | cgroup/getpeername6 |
cgroup/getpeername_unix | cgroup/getsockname4 | cgroup/getsockname6 |
cgroup/getsockname_unix | cgroup/sendmsg4 | cgroup/sendmsg6 |
cgroup/sendmsg°unix | cgroup/recvmsg4 | cgroup/recvmsg6 | cgroup/recvmsg_unix |
cgroup/getsockopt | cgroup/setsockopt | cgroup/sock_release |
struct_ops | fentry | fexit | freplace | sk_lookup }
ATTACH_TYPE := { sk_msg_verdict | sk_skb_verdict | sk_skb_stream_verdict |
sk_skb_stream_parser | flow_dissector }
METRIC := { cycles | instructions | l1d_loads | llc_misses | itlb_misses | dtlb_misses }
OPTIONS := { {-j|--json} [{-p|--pretty}] | {-d|--debug} |
{-f|--bpffs} | {-m|--mapcompat} | {-n|--nomount} |
{-L|--use-loader} }
perf和prog子命令可用于查找并打印tracing类型的BPF程序。本节未涵盖的bpftool(8)功能还包括:附加程序、读写map、操作cgroup,以及列出BPF支持特性等。
bpftool perf
perf子命令用于显示通过perf_event_open()接口附加的BPF程序。这是BCC和bpftrace程序 在Linux 4.17及更高版本中使用的常见方式。
例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# bpftool perf
pid 1765 fd 6: prog_id 26 kprobe func blk_account_io_start offset 0
pid 1765 fd 8: prog_id 27 kprobe func blk_account_io_done offset 0
pid 1765 fd 11: prog_id 28 kprobe func sched_fork offset 0
pid 1765 fd 15: prog_id 29 kprobe func ttwu_do_wakeup offset 0
pid 1765 fd 17: prog_id 30 kprobe func wake_up_new_task offset 0
pid 1765 fd 19: prog_id 31 kprobe func finish_task_switch offset 0
pid 1765 fd 26: prog_id 33 tracepoint inet_sock_set_state
pid 21993 fd 6: prog_id 232 uprobe filename /proc/self/exe offset 1781927
pid 21993 fd 8: prog_id 233 uprobe filename /proc/self/exe offset 1781920
pid 21993 fd 15: prog_id 234 kprobe func blk_account_io_done offset 0
pid 21993 fd 17: prog_id 235 kprobe func blk_account_io_start offset 0
pid 25440 fd 8: prog_id 262 kprobe func blk_mq_start_request offset 0
pid 25440 fd 10: prog_id 263 kprobe func blk_account_io_done offset 0
该输出展示了三个不同的进程(PID)及其对应的多种BPF程序:
- PID 1765是一个用于实例分析的
Vector BPF PMDA代理。 - PID 21993是
bpftrace版本的biolatency(8),显示了两个 uprobes(用户态探针),分别对应bpftrace程序中的 BEGIN 和 END 探针,以及两个 kprobes(内核态探针),用于监控块设备 I/O 的开始和结束。(该程序源码详见第9章) - PID 25440 是 BCC 版本的
biolatency(8),它目前监控的是块设备 I/O 的另一个起始函数。
其中,offset 字段表示探针相对于被监控对象的偏移位置。 以 bpftrace 为例,偏移 1781920 对应于 bpftrace 可执行文件中的 BEGIN_trigger 函数,偏移 1781927 对应于 END_trigger 函数(可以通过命令 readelf -s bpftrace 进行验证)。
prog_id 是 BPF 程序的唯一标识符,可以通过以下子命令打印出来。
📌 小结对比:
| 对比点 | bpftrace | bpftool |
|---|---|---|
| 类型 | 动态脚本语言 + 编译器 | 命令行工具 |
| 目的 | 编写、编译、运行 BPF trace 脚本 | 管理、调试、监控 BPF 程序 |
| 编译引擎 | 使用 LLVM(生成字节码) | 不生成 bpftrace 脚本的字节码 |
| 是否依赖彼此 | ❌ 无直接依赖 | ❌ 不与 bpftrace 交互 |